정렬 알고리즘은 말 그대로 데이터를 특정한 기준에 따라 순서대로 나열하는 알고리즘으로 정렬마다 시간 복잡도와 공간 복잡도에서 차이를 보이기 때문에 상황에 맞게 정렬 알고리즘을 선택하여 사용한다.
정렬은 크게 시간복잡도에서 O(N²)을 가지는 정렬과 O(NlogN)을 가지는 정렬로 나눌 수 있는데 시간 복잡도가 높으면
공간복잡도를 낮게 가져가고 반대로 시간 복잡도가 낮으면 그만큼 공간복잡도를 높게 가져가는 양상을 보인다.
시간복잡도가 O(N²)인 정렬은 선택정렬, 삽입정렬, 버블정렬이 있고 O(NlogN)인 정렬은 병합정렬, 퀵정렬, 힙정렬로 구분할 수 있다.
[선택 정렬] - O(N²)
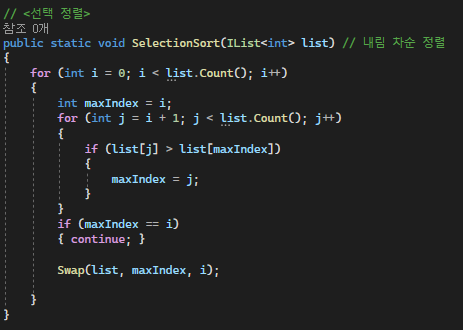
주어진 리스트에서 최소/최대값을 찾아 맨 앞부터 순서대로 정렬하는 방식이다.
아래의 코드에선 list의 요소를 순회하여 가장 높은 값을 갖는 maxIndex를 찾아 앞에서부터 값을 채우는 방식을 갖고 있다.
시간 복잡도는 O(N²)를 갖고 공간 복잡도에서는 O(1)을 갖으며 구현이 매우 간단하지만 데이터의 크기가 클 경우 비효율적일 수 있다.

[병합 정렬]
앞서 배운 분할 정복 방식을 사용하여 리스트를 반으로 나눈 후 ,정렬하고 병합하는 방식이다.
시간 복잡도가 N²에 비하면 빠른 N logN으로 대규모 데이터에서 효율적이며 안정적이고 빠른 알고리즘이지만 추가적인 데이터 공간이 필요하고 구현이 복잡하다는 단점이 존재한다.


이처럼 병합 정렬은 쪼개 내려가 왼쪽 요소와 오른쪽 요소를 비교하여 일정 기준으로 각 요소들을 정렬 배열에 넣고 이 정렬된 배열들을 다시 상위 분기로 올라가 또다른 왼쪽/오른쪽 요소가 된다.
[퀵 정렬]
퀵 정렬은 하나의 피벗, 즉 기준점이 되는 값을 정하고 이 피벗을 기준으로 작은 값과 큰 값을 2분할 하여 정렬하는 방식이다.
평균적으로는 O(NlogN)의 시간 복잡도를 가지지만 최악의 경우 O(N²)의 시간 복잡도를 갖는다.
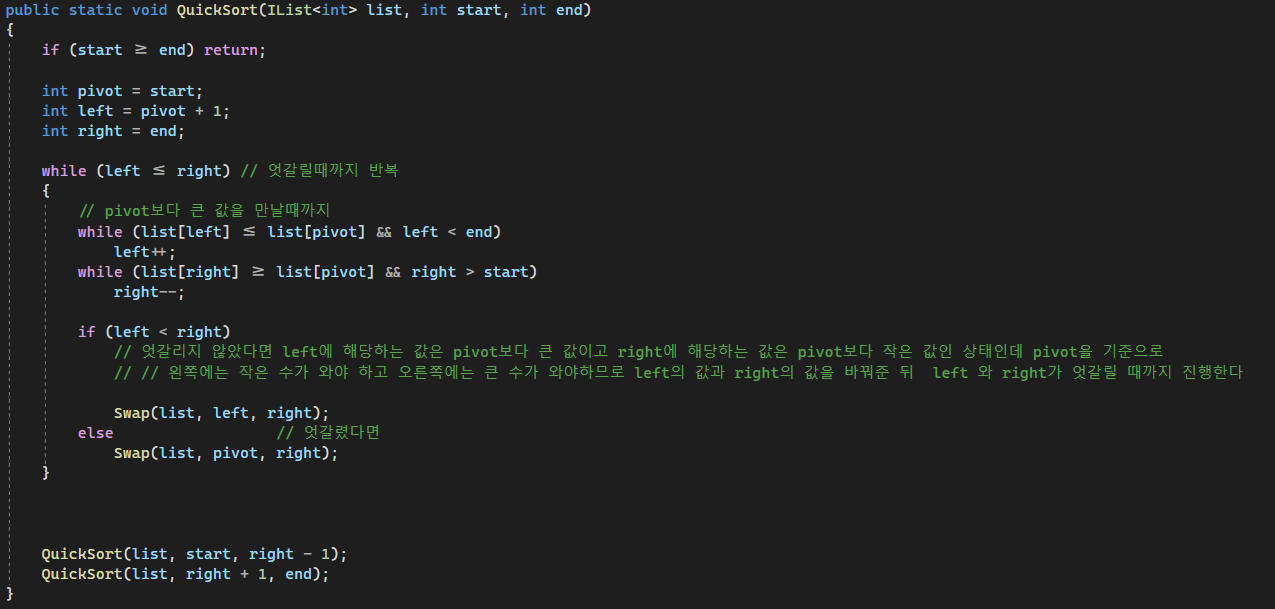
퀵 정렬도 병합 정렬과 마찬가지로 분할 정복 방식을 사용한다. 또 추가적인 메모리 공간을 필요로 하지 않고 입력 배열 내에서 정렬을 수행한다. 이로 인해 메모리 사용이 적다는 점이 장점이다.
하지만 위에서 언급한 최악의 경우 O(N²)의 시간 복잡도를 가질 수 있는데 이 때는 이미 정렬된 리스트나 거의 정렬된 리스트에서 맨 처음이나 맨 끝 값을 피벗으로 선택한 경우, 그리고 피벗을 기준으로 데이터를 나눌 때 피벗을 중심으로 한 쪽 부분의 크기가 지나치게 클 경우 혹은 작을경우에 발생하게 된다.
이러한 상황이 발생하게 될 경우 분할 정복의 장점을 활용하지 못하게 되고, 부분을 재설정 하는 과정에서 정렬된 데이터를 무시하거나 피벗을 제대로 선택하지 못해 추가적인 재설정이 불필요하게 발생하기 때문에 결과적으로 시간 복잡도가 O(N²)에 가까워지게 된다.
[힙 정렬]
힙 정렬은 말 그대로 우선순위 큐에서도 쓰이는 이진 힙 형식을 이용하여 우선순위가 가장 높은 요소가 가장 마지막 요소와 교체된 후 제거되는 방법을 이용한다.
공간 복잡도로 O(N)을 갖는 병합 정렬이나 최악의 경우 시간 복잡도 O(N²)을 갖는 퀵 정렬에 비해 힙 정렬은 시간 복잡도 O(NlogN)와 공간복잡도로 O(1)을 갖기 때문에 시간복잡도와 공간복잡도에서 각각 우위를 갖는 힙 정렬을 사용하면 되는게 아닌가 라는 생각을 할 수 있다.
하지만 힙 정렬도 단점이 존재한다. 컴퓨터 구조상 캐시 메모리를 사용해서 프로그램의 성능을 향상시키는데 이의 경우 연속된 메모리 위치에 저장된 데이터에 대해 캐시 적중률이 높아지게 된다. 일반적으로 사용하는 배열과 그로부터 파생된 자료구조들의 경우 메모리 상으로 연속된 메모리 주소를 갖기 때문에 캐시 메모리로 정보를 가져갈 때 높은 캐시 적중률을 갖게 되지만, 데이터가 연속적으로 배치되어 있지 않은 힙 구조의 경우 데이터 자체는 배열에 담을 수 있지만 왼쪽 오른쪽 자식에 접근하고자 할 때는 인덱스를 몇 번이고 건너뛰는 상황이 발생하기 때문에 캐시 적중률이 낮은 문제점이 발생한다.
이렇게 캐시 적중률이 낮은 문제점은 c#에서 연속된 주소를 갖지 않는 연결 리스트도 같이 갖는 문제점이기도 하다.

'컴퓨터 언어 > 알고리즘' 카테고리의 다른 글
| 다익스트라 알고리즘 (0) | 2023.12.07 |
|---|---|
| DFS , BFS (0) | 2023.12.04 |
| 알고리즘 설계기법 (0) | 2023.11.22 |


